- Return to book
- Review this book
- About the author
- Introduction
- 1. Digital Security for Journalists A 21st Century Imperative
- 2. The Law: Security and Privacy in Context
- 3. The Technology: Understanding the Infrastructure of Digital Communications
- 4. The Strategies: Understanding the Infrastructure of Digital Communications
- 5. Looking Ahead
- 6. Footnotes
The Technology: Understanding the Infrastructure of Digital Communications
Prologue: The Design Imperative of the Internet
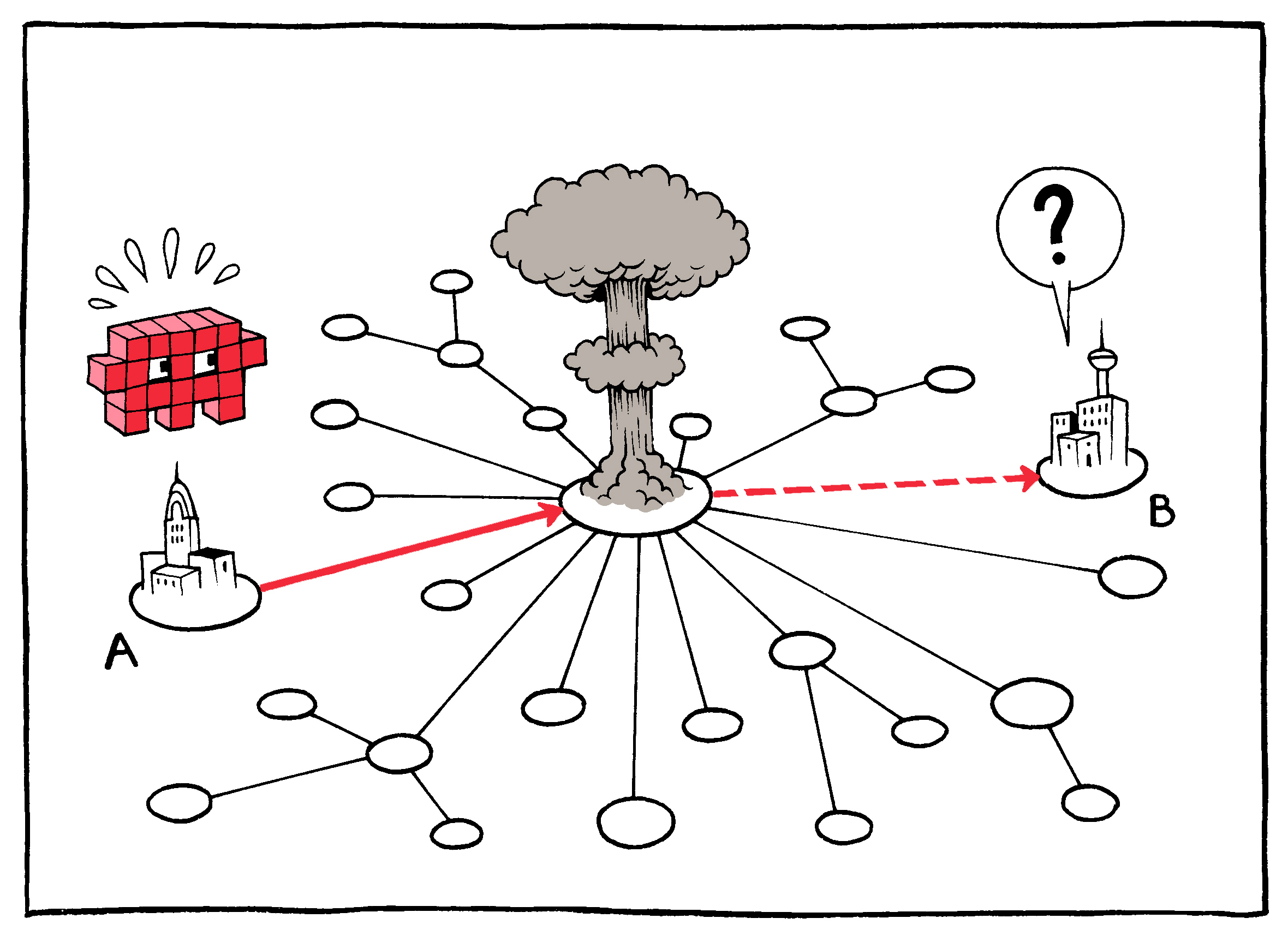
The essential framework for the design of the modern Internet was first described by Paul Baran in a 10-page paper published in March of 1964. Issued as part of the IEEE’s “Transactions of the Professional Technical Group on Communications Systems,”28 the introduction to the paper–entitled, “On Distributed Communications Networks”–begins with the following sentence:
“Let us consider the synthesis of a communication network which will allow several hundred major communications stations to talk with one another after an enemy attack.”
The paper goes on to describe the salient features of such a network, designed as a direct response to the most terrifying threat of the then-ongoing Cold War: a large-scale, long-range, distributed attack on American soil.
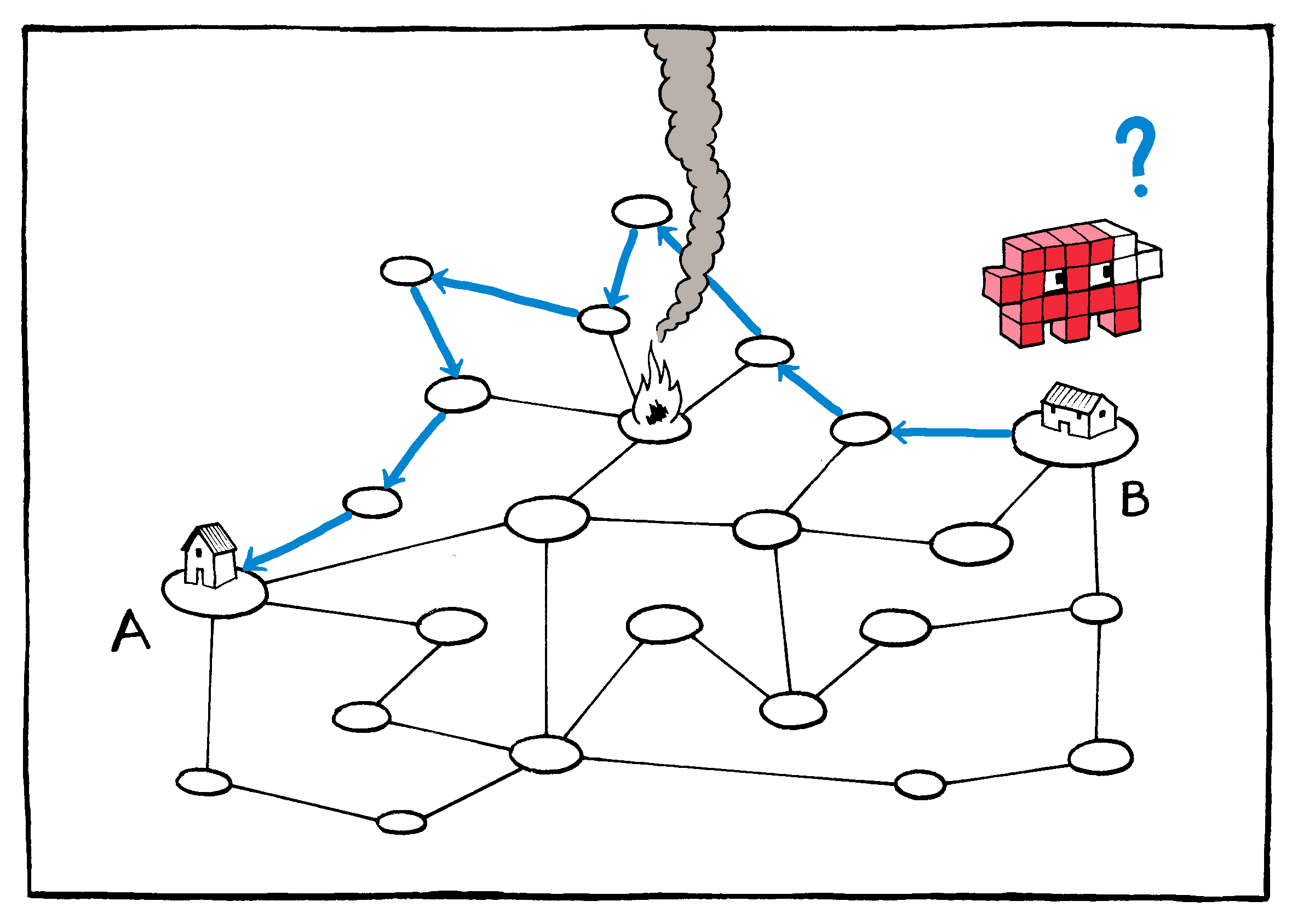
Just as George Washington forewent postal mail and employed private couriers to send messages to his troops29 during the Revolutionary War, the U.S. military sought to guarantee the integrity and availability of its own communications in case of a substantial attack on commercial networks during the Cold War. Achieving this, however, required that the system be all of the things that the telephone system of the day was not: distributed, redundant, asynchronous, relatively unpredictable, and cheap. Rather than requiring the synchronous, persistent connections of telephony, which transmitted information through the hubs and spokes of a decentralized network, the Internet would function something like an automated, multi-hop telegraph: Digital messages would be broken into pieces and individually addressed to the destination on the sender’s end, then collected and reassembled at the other.
 Centralized and decentralized networks fail quickly in the case of
malfunction or destruction.
Centralized and decentralized networks fail quickly in the case of
malfunction or destruction.
As anyone who has ever chosen the “ship as items become available” option knows, there is advantage to breaking up “deliveries” in this way. Packages (or in the case of the Internet, packets) can be routed opportunistically, moving toward their destination along whichever delivery path is most readily available. In addition to maximizing capacity, this approach also provides a certain level of unpredictability: Not even the operator of the system, much less an adversary, can know with complete certainty what the paths of these packets will be.
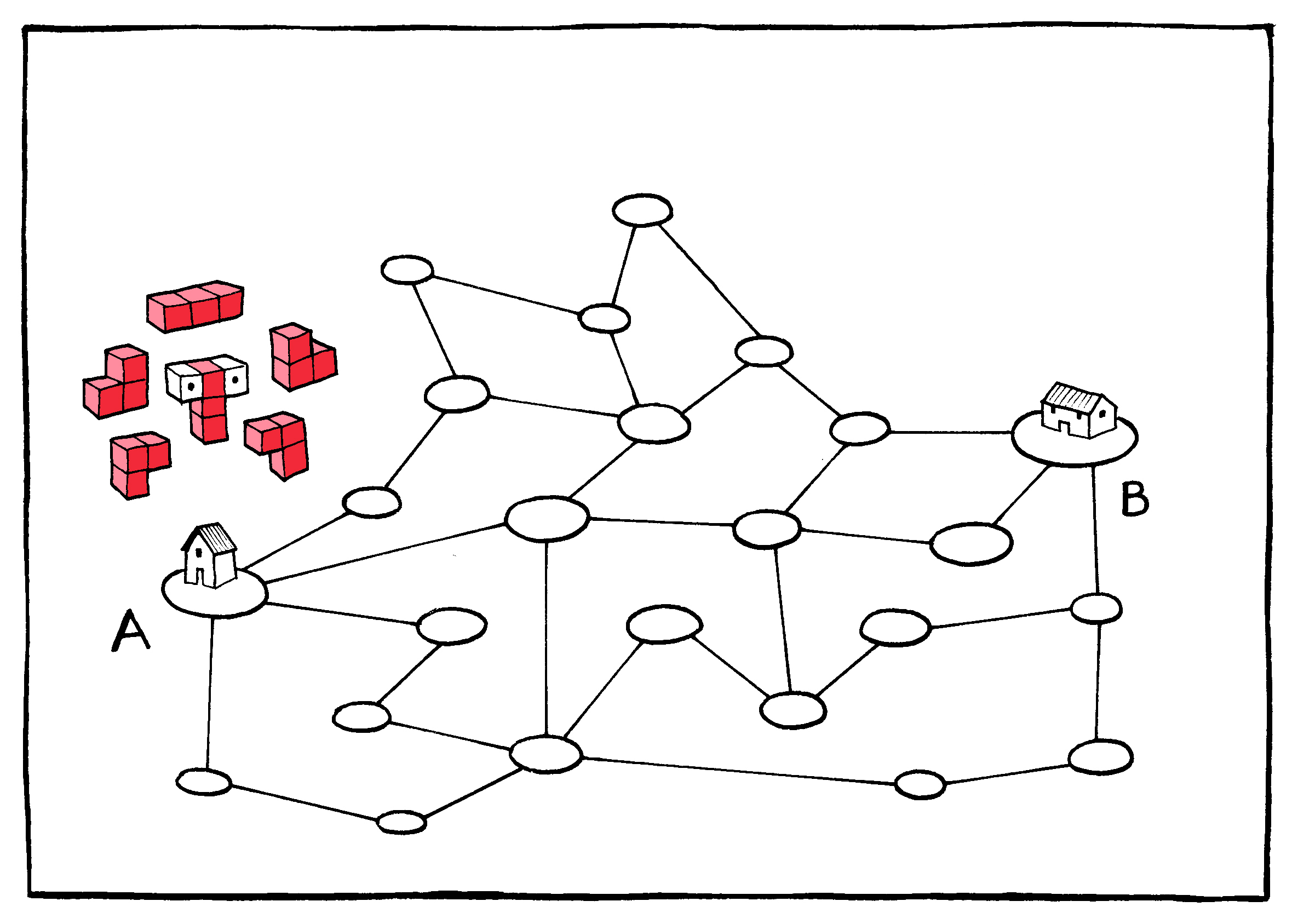 All Internet traffic is broken up into equal-sized
packets.
All Internet traffic is broken up into equal-sized
packets.
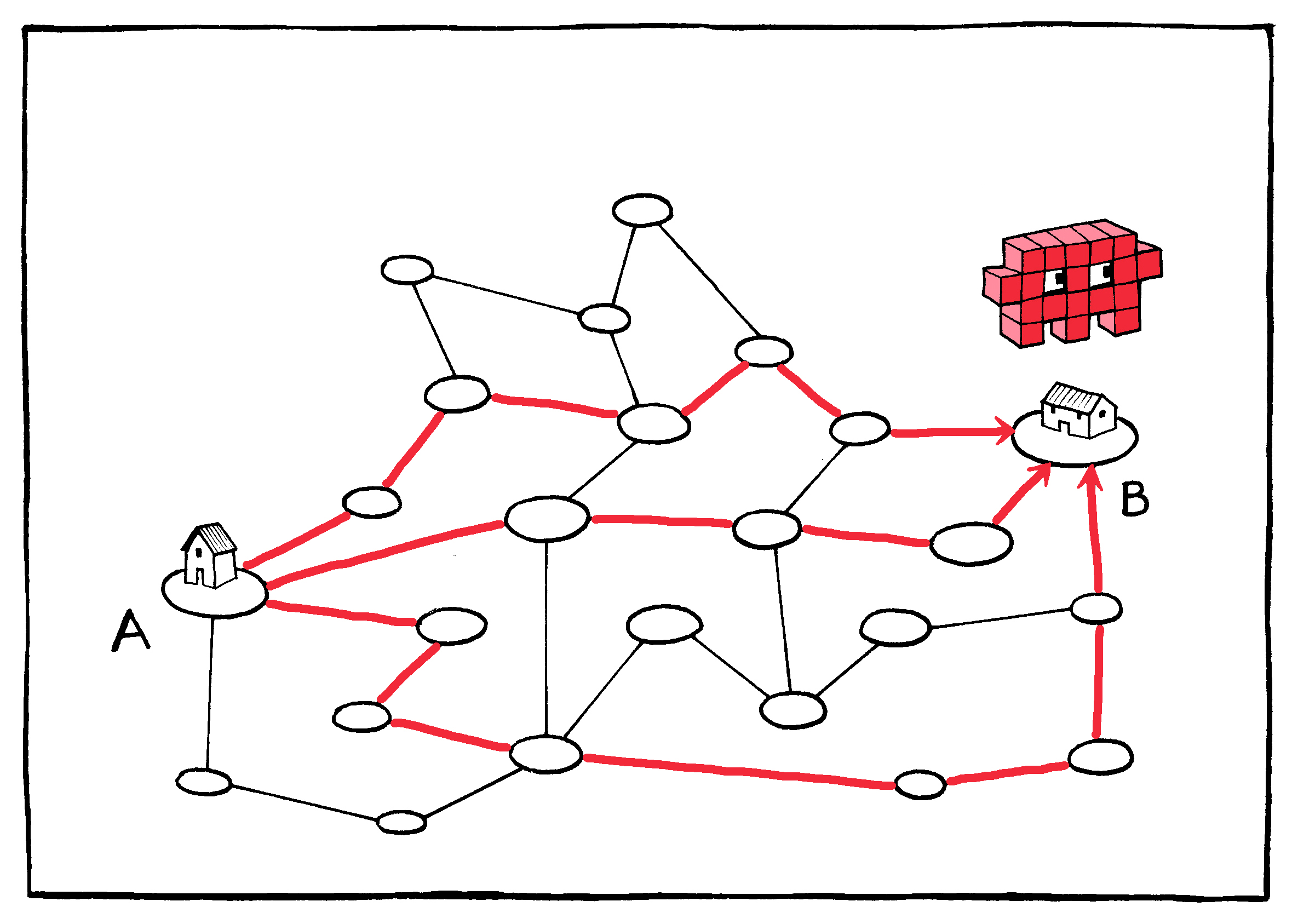 Data packets take independent paths across the Internet once they
leave your service provider.
Data packets take independent paths across the Internet once they
leave your service provider.
Because the packets are small, there is room for redundancy: The same packets can be cheaply sent multiple times to ensure delivery. This means that the cost of losing any given packet is small; if the first copy doesn’t reach the destination, the second or third will. In the worst case scenario, the packets’ return address can be used to ask for any found missing.
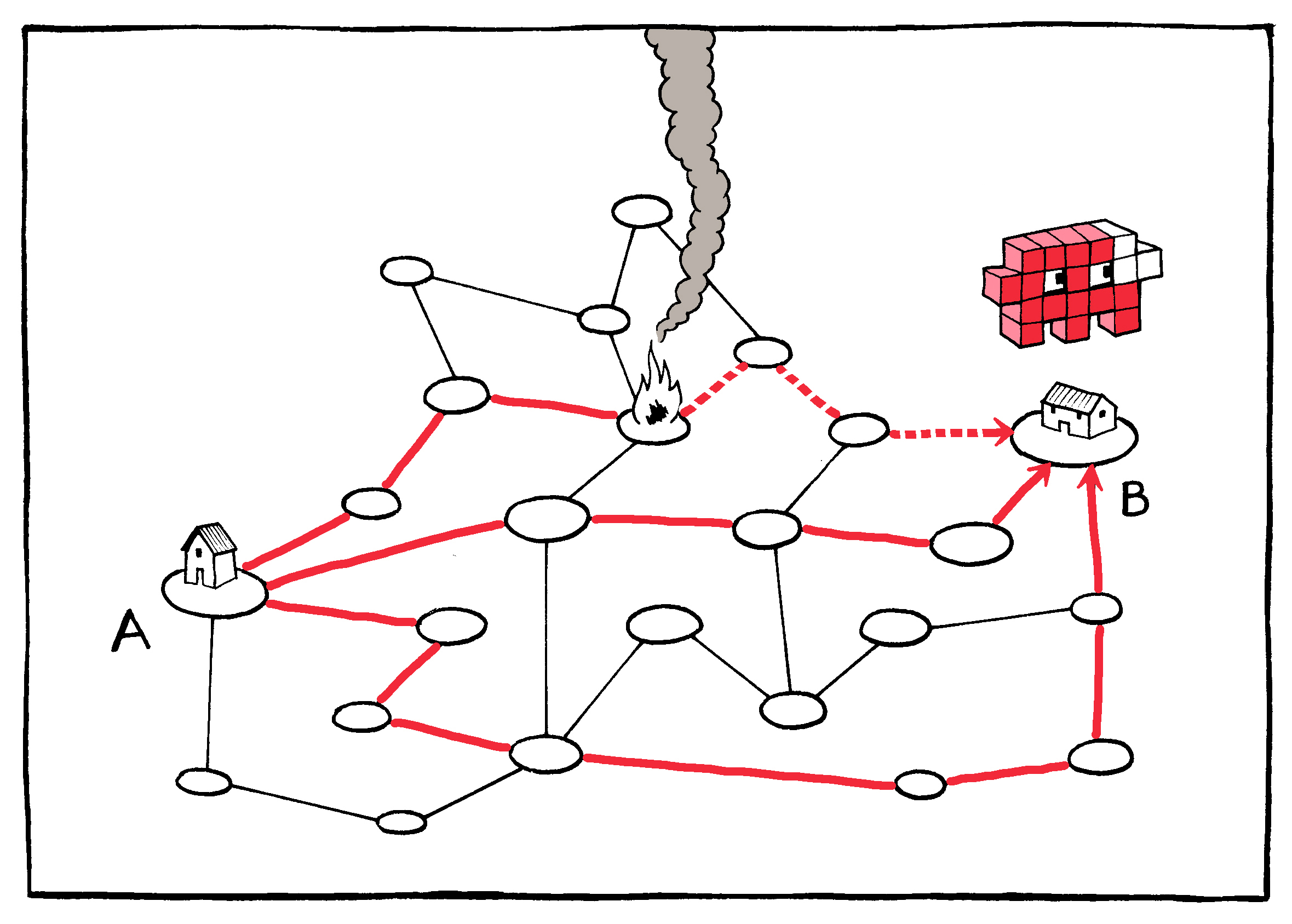 Data packets may be regularly dropped or lost in
transit.
Data packets may be regularly dropped or lost in
transit.
 If the recipient device discovers a piece missing, it can request
another copy.
If the recipient device discovers a piece missing, it can request
another copy.
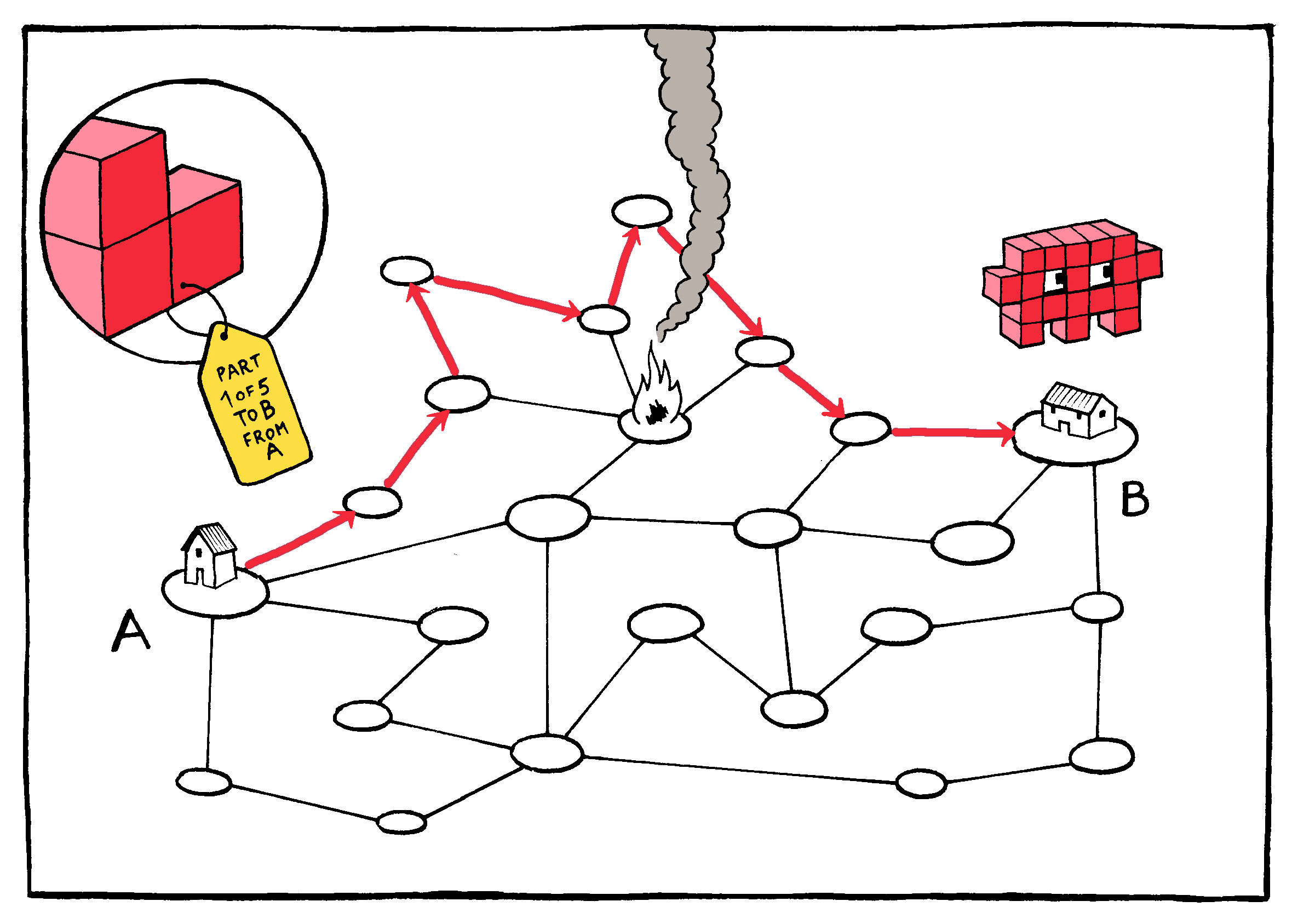 This request is made possible by the requirement that packets travel
with a “return address.”
This request is made possible by the requirement that packets travel
with a “return address.”
At the infrastructure level, this cheap redundancy–especially coupled with the return-address safety net–ensures that neither the individual routing nodes nor their actual connections to one another need be especially reliable. Connections may be intermittent or interrupted; nodes may malfunction or be destroyed. This means that the stations themselves can be both cheap and plentiful–and the more plentiful the nodes, the more resilient the network. Or, as Baran put it, the distributed network of the Internet is one:
“…in which system destruction requires the enemy to pay the price of destroying n of n stations. If n is made sufficiently large, it can be shown that highly survivable system structures can be built, even in the thermonuclear era.”30
In other words: an atomized communications solution for the atomic age.