- Return to book
- Review this book
- About the author
- Introduction
- 1. Digital Security for Journalists A 21st Century Imperative
- 2. The Law: Security and Privacy in Context
- 3. The Technology: Understanding the Infrastructure of Digital Communications
- 4. The Strategies: Understanding the Infrastructure of Digital Communications
- 5. Looking Ahead
- 6. Footnotes
Understanding the Internet
The vulnerabilities that your data faces in terms of observation, collection, and manipulation–both legal and illegal–stem directly from some of the essential features of the system described above. In order to function, the network of nodes and links that comprise the Internet requires certain information (target and return addresses, for example) to be attached to every data packet it sends. Moreover, the distributed nature of the system means that this information is seen by a large number of nodes and the parties that operate them.
Yet while we have little control over the exposure of metadata like the “to” and “from” addresses of our emails, choosing the right connection methods and using the right tools appropriately can reduce the general observability of our data as it traverses the Internet. By coupling an understanding of how digital communication systems work with the capacities of secure-communications tools, we can develop and adapt effective strategies for improving the privacy of our communications with sources and colleagues.
Getting to the Web
In the first incarnation of the commercial Web, the number of hands that touched your data on its way to and from the Internet was especially apparent. Accessing the Internet required that you wire your computer to a physical modem which was itself plugged into a telephone line and had it call a dedicated Internet service provider (ISP) when you wanted to connect. Because users typically paid by the minute and Web indices like Yahoo and Google did not yet exist, ISPs like America Online (AOL) often leveraged their gatekeeper status, funneling users through a proprietary landing page, with the broader Web only accessible beyond its threshold. In this configuration, the parties who could “see” our online activity were fairly apparent: the telephone company that received the call, and the ISP whose portal we used to send and receive data from the Web.
Though most of the visible signposts have since disappeared, our digital information passes through the same sets of hands today. In most cases, in fact, only two things have changed. In 2014, our telecom provider and Internet service provider will likely be one and the same, and our actual access to the Web–whether on a computer, phone, or tablet– is probably wireless. While undoubtedly convenient, these changes also mean that today the records of our online activities are concentrated in fewer and fewer hands, and as we walk around with our devices, the default configuration of our digital “return addresses” provides a more and more minute trace of our physical movements.
Let’s Get Physical
Computers, mobile phones, and tablets are our tangible interfaces to the networked digital world. At some point, as they send and receive information over the Web, all of those virtual messages have to find their way back to the correct physical device so that we can access that email or load that news story. In the case of wireless routers, any number of devices may be connected to the same data “pipe.” In order to correctly send and return all those little data packets that make up a Web page or even a Tweet, a wireless router must be able to uniquely identify each individual device. To make this possible, every Internet-enabled device on earth is assigned a unique machine address code (MAC) at the time of manufacture. By combining pieces of this ID with pieces of its own address, wireless routers are able to accurately exchange information with the Web on behalf of dozens of devices at a time.
The MAC address is a set of six semicolon-separated letter/number pairs: the first three sets comprise the “vendor id” indicating the device manufacturer, such Apple or Sony. The second three sets are the “device” ID.
Getting Connected
When a computer or wireless device is looking for a connection, it essentially does so by shouting its MAC out to the world and waiting for a router to respond, like a digital version of the kids’ game “Marco Polo.” The wireless router then uses the latter half of that MAC to create a temporary ID for your device, which it will store along with a variation on the Internet protocol (IP) address that the router itself has been assigned by your ISP. While the former is used to send information from the router back to your device, the latter is used as the “return address” for the information your device sends out to the Web. Because each of these is created anew every time your device connects to the router, your device’s “return address” will change slightly each time you connect.
In a well-managed system your device’s MAC should never move past the router. A malicious party operating the router, however, can capture this information.
Likewise, though IP addresses are designed to describe the geography of the digital world, they have a direct mapping to the physical world as well. This is not an accident; the opportunistic routing of the Internet only works if a node can tell which of its neighbors is the closest to the final destination marked on the particular packet. This is the layer at which digital and physical location correlate: For the ISP, a, IP address can be mapped, not just to a general geographic vicinity, but all the way down an individual router.
This illustrates just one of the ways in which our digital activities can be mapped to our physical identities: Not only does our ISP know the precise location of individual routers, it knows who pays the bills for them, including name, address, and credit card or other financial information. Since all of these are available for subpoena under the ECPA rules mentioned above, it is easy to see how Web browsing–more so from the home–is almost never substantively “private,” especially from law enforcement or other government entities.
In point of fact, the wireless router in your home (if you use one) is not the only router through which your Web traffic is likely to pass. Almost all major ISPs have even larger routers that they use to route traffic from their customers in a particular geographic area out to the broader Web. Typically it is actually this latter, more general IP address that is visible to the broader Internet.
You can view your own current IP address by visiting: What’s my IP?
Your Data’s Identity
In the course of a day, most of us connect to the Web from at least several wireless access points–even more when we consider our mobile devices. Unfortunately, the “return address” IP information our data packets carry with them is by no means the only, or even the most granular, data that our Web activities carry with them. A great deal of information is stored in the software we use to actually access the Web: namely, Web browsers and apps. For example, most browsers share information about your operating system and browser type with websites, primarily so that they can provide you with the best user experience.
Most websites can see - and log - the time, your browser type, and your location.
Added to this, Web “cookies” - small bits of text stored on your hard drive via your browser - can be used to track your Web activity.
See “How cookies track you” for more.
Though cookies set by one website cannot be detected or read by another, companies like Google can set cookies on so many sites that even their cookies alone can uniquely identify a user;31 programs that can access browsing history can do this as well.32 This browser “fingerprint” can be used to draw together otherwise disparate threads of Web activity, and revealing your own identity and potentially that of a source.
Thus, every time we request a Web page, we are not only locating ourselves to our service provider, but fingerprinting and timestamping our traffic across locations, like thousands of pieces of digital registered mail. Moreover, even if the resolution of our “return address” is not particularly granular to the outside Web, there are other ways that our digital “fingerprint” can be connected to our physical identity. This is exactly what we do when we log in to a Web service, be it Facebook, or Gmail, or Twitter, or Amazon.com. To these providers–or anyone who is eavesdropping on their communications or who has access to their logs–the browser fingerprint, digital-geographic “return address” and physical identity of Web activity is not only timestamped and transparent, but highly detailed and often verified, through billing or other personal information.
Though our device’s exact “return address” on a network will change slightly each time one reconnects, browser fingerprints tend to change little over the course of weeks or even months. Once linked to your real identity, it can be used fairly effectively to track your activity on the Web across swathes of time and space.
The above applies regardless of which type of wireless device one uses to connect to the Internet: Laptops, tablets, and Internet-enabled mobile phones all employ these same mechanisms. Of course, given the constant signal hand-off among cell-towers required in order for you to walk down the street with a mobile device and carry on a phone conversation, load a Webpage, or provide required emergency services access, your service provider can physically pinpoint your phone to within 50 to 300 meters at any given time.33
What About the “Bad” Guys?
Until this point, we have been considering data collection, retention, and access that fall within the current business and legal norms of the United States. Whether these meet our personal preferences or professional requirements, they represent the default operating environment for digital communications when, in effect, all parties are following the rules.
But there are other players on the system as well. Hackers, identity thieves and hostile observers may also wish to track our behavior, identify us, and access or manipulate our accounts. Though we cannot control what metadata will be sent along with our information requests over the Web, we do have some choices about how it is sent. Making these choices wisely can have an enormous impact on the relative visibility of our Web activity to unauthorized observers.
Nothing But Noise
Whether bridging the physical gap between your device and a wireless router or sending data across the network to and from a website, there are two broad classes of connections available in each case: unsecured and secured. In an unsecured connection, information sent between the two points is transmitted in “clear” or “plain” text–as readable as this sentence to any party watching. With a secured connection, at least some level of encryption–essentially scrambling of the message–is applied before information is sent over the network, drastically reducing the ability of outside observers to infer what’s being sent. As we will see below, these situations are analogous to sending and receiving postcards and letters (in envelopes), respectively.
Not surprisingly, the information that an observer can see depends upon his or her position in the network. If you connect to an unsecured wireless network, your Web activity (what pages you are visiting and so on) is potentially observable by any other device on that same network
For example, see Julian Oliver’s “Reconstructing images from Web traffic”
. If you connect to an unsecured website, the information you are sending back and forth to that website is potentially observable by anyone with access to one of the nodes on the network that passes it along. At a given moment, this would include anyone with access to the router you’re connected to and the Internet service provider that links that router to the wider Web. Though questionable, “sniffing” packets on the broader Web is more than possible.34
Wireless-level Security
In practice, using an unsecured wireless network is somewhat analogous to shouting your order across a crowded restaurant rather than waiting for someone to come and take your order at your table. What you’re sending and receiving can be heard by anyone in the room who chooses to listen: Your device is speaking in a language that anyone can understand.
 An unsecured wireless connection means other devices can easily
“overhear” the data your device sends and receives.
An unsecured wireless connection means other devices can easily
“overhear” the data your device sends and receives.
In a secure connection, however, communication begins with a kind of one-to-one greeting process. Your device identifies the router and sends it a short message, indicating that you would like to connect. The router then replies to your message with a randomly generated nonsense string that both devices will use as the basis for a kind of elaborate Pig Latin in which all of your messages will be exchanged from that point on. Thus, while your device is still sending all its messages across the room, those messages are protected in such a way that only your device and the router can “hear” what is being sent.
“WPA2 enterprise” security is most robust; though “WPA2 home” has some vulnerabilities, both are far preferable to an unsecured network.
 In a secure connection, the messages that devices exchange with the
router are protected.
In a secure connection, the messages that devices exchange with the
router are protected.
Small s, Big Significance
When it comes to connecting to a website, one also has the choice between a secure and an insecure connection. At any given moment you can tell which type of connection you are using simply by looking at the url bar of your browser window–the location will start with either http or https. The significant difference between these two lies in the little s at the end of the second; it stands for “secure.”
What does it mean for your connection to a website to be secure? In effect, it is much the same as in the case of the wireless connection described above: A secured connection means that the information you are sending back and forth to that website is encoded in such a way that your messages look like gibberish to anyone observing.
At the same time, there is an important difference between communicating with a router that is in the same room as you are (or very nearby) and communicating with a website that may be on the other side of the world. In a coffee shop or library, there is almost always a third party–a person, maybe a sign–that provides the name of the network you should connect to, and (if it is secure) its password. Though most of us assume this information is correct if we’re able to successfully connect to the Internet, our decision to use that network also implies a good deal of trust: We trust that the router is properly secured, and even that it is the router it claims to be. If we are familiar with the business or organization we may not give this a second thought, in the same way that we routinely trust waiters and salespeople not to abuse our credit card information. Yet it is important to remember that this expression of trust is implicit in our decision to connect.
On the broader Web, we also need someone to vouch for the fact that the website we’re connecting to is actually the one we think it is, because it’s also incredibly easy to make one website look like another. In fact, even if you type the URL of the website you want to visit directly into your browser’s url bar, it’s possible to end up at a website that only looks like the one you intended to visit. This is also how some Internet censorship is implemented,35 as was seen recently in Turkey.
So how can you be sure that the secure connection you establish is to the website you’re actually looking for? In practice this is made possible by the fact that https connections don’t just establish secure communications willy-nilly. Before agreeing to encode your communications with a website, your browser first asks it for identification, in the form of a security certificate. These certificates work something like digital passports for the Web. They are issued by certificate authorities which generally provide them after running a kind of background check on the website, making sure that it is actually owned by the company or individual who claims to run it.36 Before agreeing to establish a secure connection to a website via https, your browser asks the site for this “passport,” and then checks with the issuing authority to make sure it is authentic.
This part of the process is known as “authentication.”
If the credentials check out, your browser moves on to the next step and actually establishes an encrypted connection. Otherwise, it will throw up a warning, letting you know that something’s not right.
 A valid security certificate means your browser will establish a
secure and trusted connection.
A valid security certificate means your browser will establish a
secure and trusted connection.
 A bad security certificate will cause your browser to throw up a
warning.
A bad security certificate will cause your browser to throw up a
warning.
What an Authenticated, Encrypted Connection Means, and What It Doesn’t
So let’s say that at this point you’ve connected to both a router and a website securely. Does that mean that no one can see what you’re doing on the Web? Not quite. Remember that the information you send to and from that website still has to find its way from your device to the website and back again. To do this, every node along the route needs access to some information about your messages in order make sure they get to where they’re going. This is where our metadata comes back into play: Every node on the network still needs to know where each message is coming from and where it’s going. In this sense, your encrypted Web traffic is something like mail in a very sturdy envelope; anyone can see where it’s coming from and when, as well as where it’s going. But only your device and the website you’re communicating with can open the envelope to see what’s inside. By contrast, if you connect to a website via http, it’s more like sending your information via hundreds of postcards; not only can every node that handles it see where it is coming from and where it is going, the contents of your messages are there for anyone to read as well.
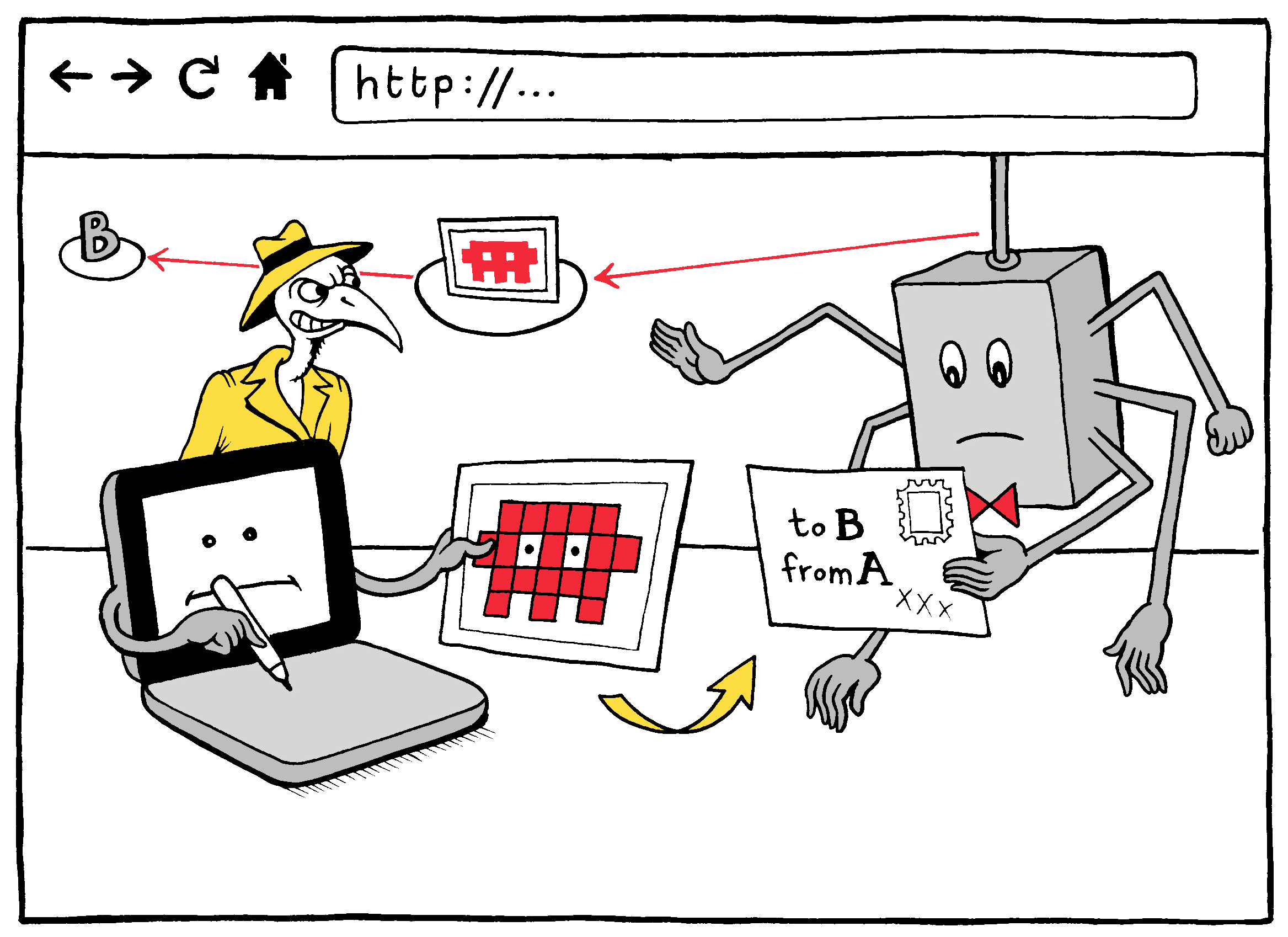 An http connection leaves all the contents of your packets visible
to anyone on the network.
An http connection leaves all the contents of your packets visible
to anyone on the network.
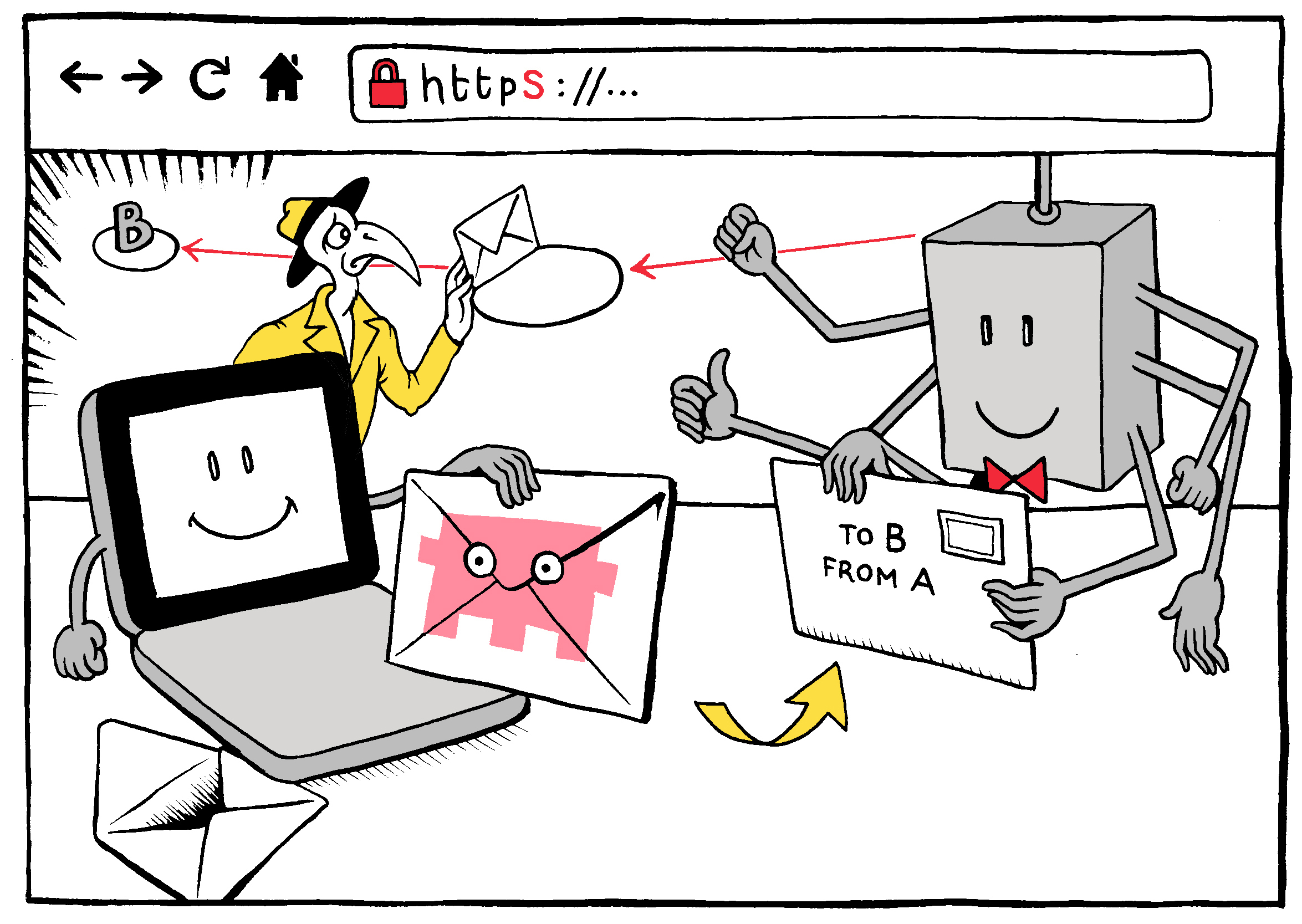 An https connection, meanwhile, protects the contents. Only the
metadata remains visible.
An https connection, meanwhile, protects the contents. Only the
metadata remains visible.
This is why using https connections is so important, especially when you are sending sensitive information like usernames and passwords. The same goes for any website where you might enter financial, medical or personally identifying information. In spite of this, many websites that ask for and deal with sensitive information don’t always require or provide https connections. Until very recently, for example, Yahoo did not require an https connection to log in to its mail service.37 Ideally, one would use https connections as much as possible. Fortunately, however, the Electronic Frontier Foundation recently launched a project aptly named HTTPSEverywhere, a free browser plugin that always attempts to make a secure connection, and then only revert to an insecure one if the former is unavailable. Installing this on your browsers can help make using the most secure connection available a more seamless part of your Web browsing activity.